
A coworker from our shared space kindly left these (and more) wonderful cookies for everyone ♥️
Cats, good books, AI, and religious walking in the city of Sofia
A coworker from our shared space kindly left these (and more) wonderful cookies for everyone ♥️

It’s time for the EU and other regulators to reconsider the deal we’ve made with search engines and how companies like Google are redefining it without consent.
Originally, we allowed Google and other search engines to index our content for free in exchange for traffic. This made sense: we paid for hosting, created content, and in return got visitors from search. They profited from ads and reordering the search results in favor of advertisers. But the rise of generative AI has changed the terms.
Now, Google uses our content not just to link to us, but to generate full answers on its platform, keeping users from ever visiting our sites. This shift erodes the value we once received. Meanwhile, Google and a small group of others continues to monetize the interaction through ads and AI subscriptions.
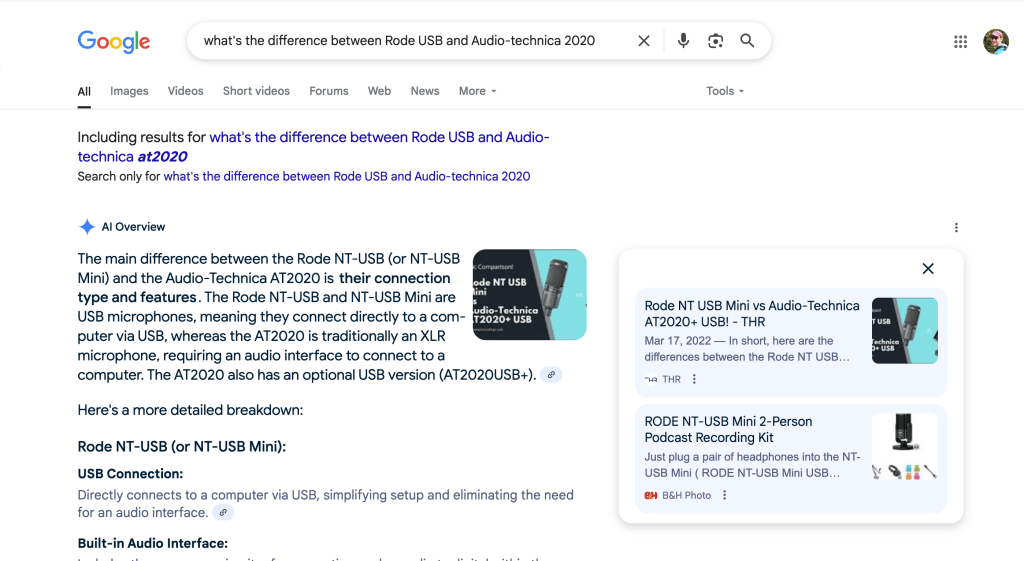
Google Search results these days barely feature any links and highlight internal content
SEO experts talk about “GEO” (Generative Engine Optimization), but the reality is that no clear playbook exists for it, and most content creators are seeing less and less return. There’s no proven way to optimize for Gemini or OpenAI’s models, especially when those tools don’t send much traffic back. The only instance of GEO I’ve seen was with a meme. Some prankster optimized (on purpose or not) a tweet about the size of Blue Whale’s vagina in comparison with a specific politician and Gemini picked it up.
At the same time, website owners still bear all the costs: paying for hosting, paying for content creation, and now even for AI tools that were trained on their own data. This suffocates the open web so that the LLM companies can sustain a hokey-stick growth to the trillions of valuation.
OpenAI at least pays for access to datasets. But many of these datasets were built through unrestricted crawling or by changing terms of services after the fact. Google doesn’t even do that. It simply applies its AI to search and displays that back to the user.
Regulation is needed yesterday. The EU’s Digital Markets Act already limits self-preferencing. Why not extend rules like it to web data? Possibilities include:
And GEO will likely turn out to be more of the same endless content spam generation to feed it into the models, exploiting knowledge about how these models scrape data. It doesn’t feel useful yet and if that’s the future, we can only expect the enshittification of generative AI.

Woodland forget-me-not. Photo taken far from any forests.
I love these little flowers.
Happy 20-year work anniversary to Donncha — the very first person to join the company, even before Matt! His post brings back the early days and shows the small group of people who started it all. They all look so young! It’s amazing to look back and see how far we’ve come. Here’s to the next 20!
I remember joining in 2011, and blaming the already 6-years-old codebase to always find Donncha’s username in the oldest corners of the code.

Photo by Mark Ralev. Thanks to Mark, I have some photos of myself from 2011.

This was the computer I used when I joined Automattic. I did my trial with it and bought a new one for my first team meetup.



And 3 of the only 4-5 photos I still have from the said meetup in 2011. The last photo features Matt and I think Stephane Daury but with the photo quality of my 2011 camera, it could also be Jason Statham.
